Exposing NSMutableArray
I’ve always wondered how NSMutableArray works internally. Don’t get me wrong, immutable arrays certainly provide enormous benefits: not only are they thread safe but also copying them is essentially free. It doesn’t change the fact that they’re quite dull – their contents can’t be modified. I find the actual memory manipulation details fascinating and this is why this article focuses on mutable arrays.
Since I more or less describe the complete process I used to investigate NSMutableArray, this post is fairly technical. There is an entire section discussing the ARM64 assembly, so if you find that boring then do not hesitate to skip it. Once we’re through the low level details, I present the non obvious characteristics of the class.
Implementation details of NSMutableArray are private for a reason. They’re subject to change at any time, both in terms of underlying subclasses and their ivar layouts, as well as underpinning algorithms and data structures. Regardless of those caveats, it’s worth peeking under the hood of NSMutableArray and figuring out how it works and what can be expected of it. The following study is based on iOS 7.0 SDK.
As usual, you can find the accompanying Xcode project on my GitHub.
The Problem of Plain Old C Arrays
Every self-respecting programmer knows how C arrays work. It boils down to a continuous segment of memory that can be easily read from and written into. While arrays and pointers are not the same (see “Expert C Programming” or this article), it’s not much of an abuse to consider “malloc-ed block of memory” as an array.
One of the most obvious drawbacks of using linear memory is that inserting an element at index 0 requires shifting all the other elements via means of memmove:
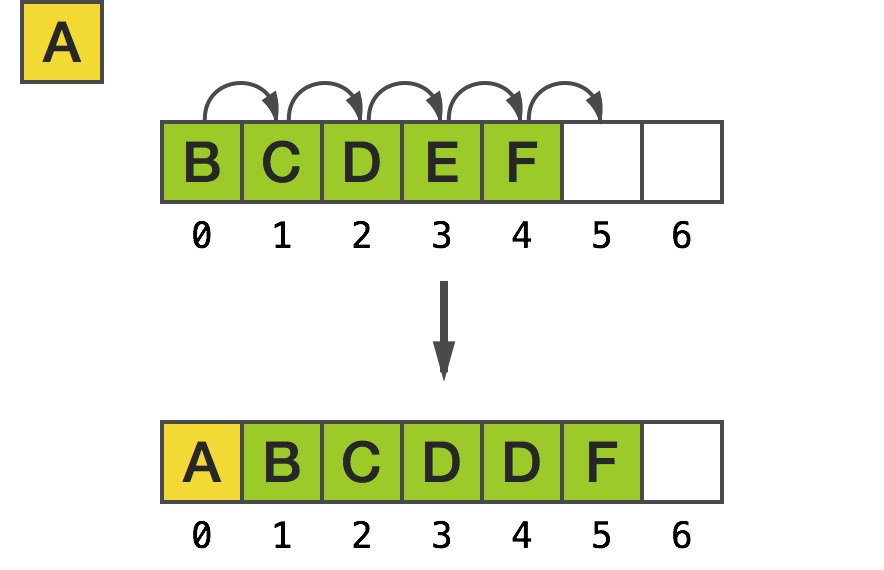
Inserting to C array at index 0
Similarly, removing the first element requires shifting action as well, assuming one wants to keep the same memory pointer as an address of the first element:
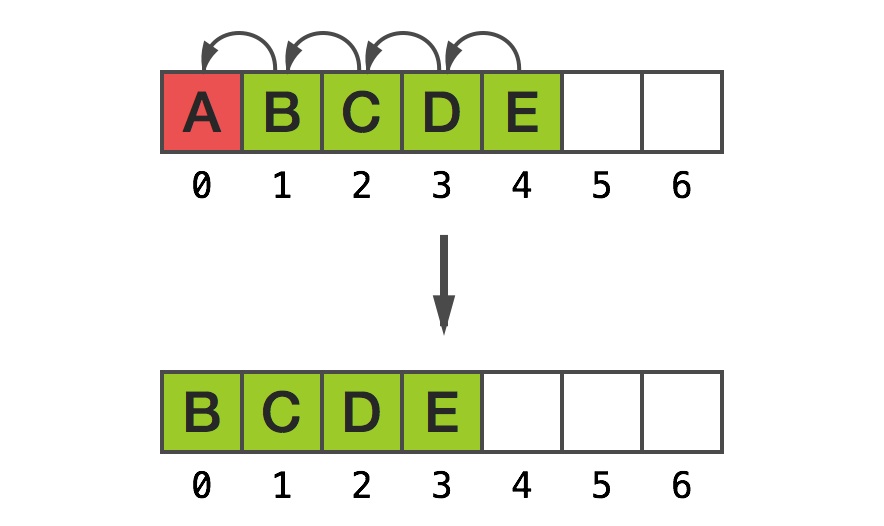
Removing from C array at index 0
For very large arrays this quickly becomes a problem. Obviously, direct pointer access is not necessarily the highest level of abstraction in the world of arrays. While C-style arrays are often useful, the daily bread and butter of Obj-C programmers wanting a mutable, indexed container is NSMutableArray.
NSMutableArray
Diving in
Even though Apple publishes source code for many libraries, Foundation and its NSMutableArray is not open sourced. However, there are some tools that make unrevealing its mysteries a little bit easier. We begin our journey at the highest possible level, reaching into the lower layers to get otherwise inaccessible details.
Getting & Dumping Class
NSMutableArray is a class cluster – its concrete implementations are actually subclasses of NSMutableArray itself. Instances of which class does actually +[NSMutableArray new] return? With LLDB we don’t even have to write any code to figure that out:
(lldb) po [[NSMutableArray new] class]
__NSArrayM
With class name in hand we reach for class-dump. This handy utility forges the class headers obtained by analyzing provided binaries. Using the following one-liner we can extract the ivar layout we’re interested in:
./class-dump --arch arm64 /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS7.0.sdk/System/Library/Frameworks/CoreFoundation.framework/CoreFoundation | pcregrep -M "^[@\w\s]*__NSArrayM[\s\w:{;*]*}"
I suck at regular expressions so the one used above is probably not a masterpiece, but it provides fruitful results:
@interface __NSArrayM : NSMutableArray
{
unsigned long long _used;
unsigned long long _doHardRetain:1;
unsigned long long _doWeakAccess:1;
unsigned long long _size:62;
unsigned long long _hasObjects:1;
unsigned long long _hasStrongReferences:1;
unsigned long long _offset:62;
unsigned long long _mutations;
id *_list;
}
The bitfields in the original output are typed with unsigned int, but obviously you can’t fit 62 bits into a 32-bit integer – class-dump hasn’t been patched yet to parse ARM64 libraries correctly. Despite those minor flaws, one can tell quite a lot about the class just by looking at its ivars.
Disassembling Class
The most important tool in my investigation was Hopper. I’m in love with this disassembler. It’s an essential tool for curious souls who have to know how everything works. One of the best features of Hopper is that it generates C-like pseudocode that very often is clear enough to grasp the gist of the implementation.
The crucial method for understanding __NSArrayM is - objectAtIndex:. While Hopper does great job providing pseudocode for ARMv7, the feature doesn’t work for ARM64 yet. I figured it would be an excellent exercise to do this manually, with some hints from its ARMv7 counterpart.
Dissecting the Method
With ARMv8 Instruction Set Overview (registration required) in one hand and a bunch of educated guesses in another I think I’ve deciphered the assembly correctly. However, you should not treat the following analysis as an ultimate source of wisdom. I’m new at this.
Passing Arguments
As a start point let’s note that every Obj-C method is actually a C function with two additional parameters. The first one is self which is a pointer to the object being receiver of the method call. The second one is _cmd which represents the current selector.
One might say that the equivalent C-style declaration of the - objectAtIndex: function is:
id objectAtIndex(NSArray *self, SEL _cmd, NSUInteger index);
Since on ARM64 these types of parameters are passed in the consecutive registers, we can expect the self pointer to be in x0 register, the _cmd in x1 register and the index of object in x2 register. For details of parameter passing please reference the ARM Procedure Call Standard, noting that Apple’s iOS version has some divergences.
Analyzing Assembly
This will look scary. Since analyzing a large chunk of assembly at once is not sane, we’re going to walk through the following code step by step, figuring out what each line does.
0xc2d4 stp x29, x30, [sp, #0xfffffff0]!
0xc2d8 mov x29, sp
0xc2dc sub sp, sp, #0x20
0xc2e0 adrp x8, #0x1d1000
0xc2e4 ldrsw x8, [x8, #0x2c]
0xc2e8 ldr x8, [x0, x8]
0xc2ec cmp x8, x2
0xc2f0 b.ls 0xc33c
0xc2f4 adrp x8, #0x1d1000
0xc2f8 ldrsw x8, [x8, #0x30]
0xc2fc ldr x8, [x0, x8]
0xc300 lsr x8, x8, #0x2
0xc304 adrp x9, #0x1d1000
0xc308 ldrsw x9, [x9, #0x34]
0xc30c ldr x9, [x0, x9]
0xc310 add x9, x2, x9, lsr #2
0xc314 cmp x8, x9
0xc318 csel x8, xzr, x8, hi
0xc31c sub x8, x9, x8
0xc320 adrp x9, #0x1d1000
0xc324 ldrsw x9, [x9, #0x38]
0xc328 ldr x9, [x0, x9]
0xc32c ldr x0, [x9, x8, lsl #3]
0xc330 mov sp, x29
0xc334 ldp x29, x30, [sp], #0x10
0xc338 ret
The Setup
We begin with what seems to be an ARM64 function prologue. We’re saving x29 and x30 registers on the stack then we move the current stack pointer sp to x29 register:
0xc2d4 stp x29, x30, [sp, #0xfffffff0]!
0xc2d8 mov x29, sp
We make some room on the stack (subtracting, since stack grows downwards):
0xc2dc sub sp, sp, #0x20
The path code we’re interested in doesn’t seem to be using this space. However, the “out of bounds” exception throwing code does call some other functions thus the prologue has to facilitate both options.
Fetching Count
The next two lines perform program counter relative addressing. The specifics of addresses encoding are quite complicated and the literature is scarce, however, Hopper automatically calculates more sane offsets:
0xc2e0 adrp x8, #0x1d1000
0xc2e4 ldrsw x8, [x8, #0x2c]
The two lines will fetch contents of memory located at 0x1d102c and store it into x8 register. What’s over there? Hopper is kind enough to help us:
_OBJC_IVAR_$___NSArrayM._used:
0x1d102c dd 0x00000008
This is the offset of _used ivar inside the __NSArrayM class. Why go through the trouble of additional fetch, instead of simply putting the value 8 into the assembly? It’s because of fragile base class problem. The modern Objective-C runtime handles this by giving itself an option to overwrite the value at 0x1d102c (and all the other ivar offsets for that matter). If either NSObject, or NSArray, or NSMutableArray adds new ivars, the old binaries will still work.
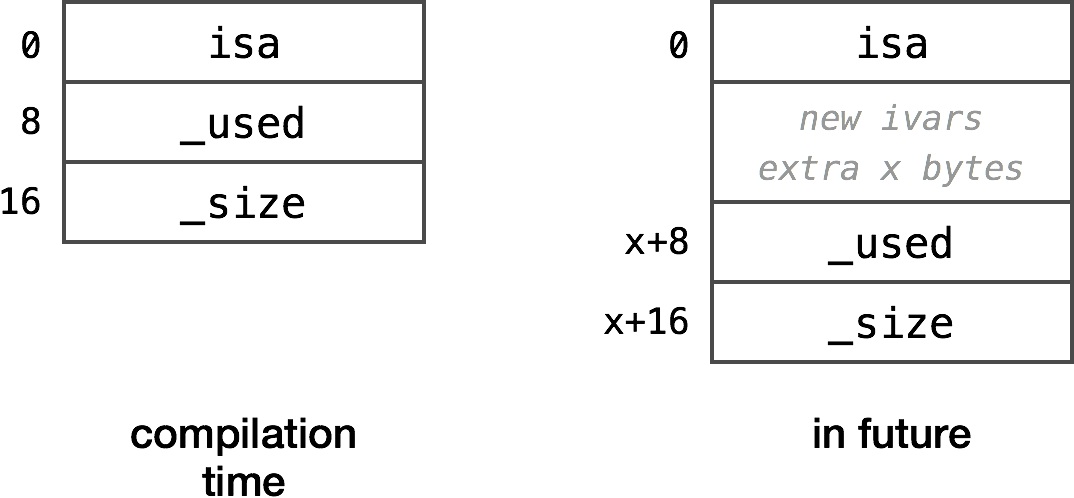
The runtime can modify the ivars' offsets dynamically without breaking compatibility
While the CPU has to do an additional memory fetch, this is a beautiful solution as explained in more details on Hamster Emporium and Cocoa with Love.
At this point we know the offset of _used within the class. And since the Obj-C objects are nothing more than structs, and we’ve got pointer to this struct in x0, all we have to do is fetch the value:
0xc2e8 ldr x8, [x0, x8]
The C equivalent of the above code would be:
unsigned long long newX8 = *(unsigned long long *)((char *)(__bridge void *)self + x8);
I think I prefer the assembly version. Quick analysis of disassembled - count method of __NSArrayM reveals that the _used ivar contains the number of elements in __NSArrayM, and as of this moment we have this value in x8 register.
Checking Bounds
Having requested index in x2 and count in x8 the code compares the two:
0xc2ec cmp x8, x2
0xc2f0 b.ls 0xc33c
When the value of x8 is lower or same as x2 then we jump to the code at 0xc33c, which handles the exception throwing. This is essentially the bounds checking. If we fail the test (count is lower or equal to index), we throw exception. I’m not going to discuss those parts of disassembly since they don’t really introduce anything new. If we pass the test (count is greater than index) then we simply keep executing instructions in order.
Calculating Memory Offset
We’ve seen this before, this time we fetch the offset of _size ivar located at 0x1d1030:
0xc2f4 adrp x8, #0x1d1000
0xc2f8 ldrsw x8, [x8, #0x30]
Then we retrieve its contents and shift it to the right by two bits:
0xc2fc ldr x8, [x0, x8]
0xc300 lsr x8, x8, #0x2
What’s the shift for? Let’s take a look at the dumped header:
unsigned long long _doHardRetain:1;
unsigned long long _doWeakAccess:1;
unsigned long long _size:62;
It turns out, all three bitfields share the same storage, so to get the actual value of _size, we have to shift value to the right, discarding the bits for _doHardRetain and _doWeakAccess. Ivar offsets for _doHardRetain and _doWeakAccess are exactly the same, but their bit accessing code is obviously different.
Going further it’s the same drill, we get the contents of _offset ivar (at 0x1d1034) into x9 register:
0xc304 adrp x9, #0x1d1000
0xc308 ldrsw x9, [x9, #0x34]
0xc30c ldr x9, [x0, x9]
In the next line we add the requested index stored in x2 to the 2-bits-right-shifted _offset (it’s also a 62 bits-wide bitfield) and then we store it all back in x9. Isn’t assembly just amazing?
0xc310 add x9, x2, x9, lsr #2
The next three lines are the most important ones. First of all, we compare the _size (in x8) with _offset + index (in x9):
0xc314 cmp x8, x9
Then we conditionally select value of one register based on the result of previous comparison:
0xc318 csel x8, xzr, x8, hi
This is more or less equal to ?: operator in C:
x8 = hi ? xzr : x8; /* csel x8, xzr, x8, hi */
The xzr register is a zero register which contains value 0, and the hi is the name of condition code the csel instruction should inspect. In this case we’re checking whether the result of comparison was higher (if value of x8 was greater than that of x9).
Finally we subtract the new value of x8 from the _offset + index (in x9) and we store it in x8 again:
0xc31c sub x8, x9, x8
So what just happened? First of all let’s look into equivalent C code:
int tempIndex = _offset + index; /* add x9, x2, x9, lsr #2 */
BOOL isInRange = _size > tempIndex; /* cmp x8, x9 */
int diff = isInRange ? 0 : _size; /* csel x8, xzr, x8, hi */
int fetchIndex = tempIndex - diff; /* sub x8, x9, x8 */
In the C code we don’t have to shift neither _size nor _offset to the right, since compiler does this automatically for bitfields access.
Getting the Data
We’re almost there. Let’s fetch the contents of _list ivar (0x1d1038) into x9 register:
0xc320 adrp x9, #0x1d1000
0xc324 ldrsw x9, [x9, #0x38]
0xc328 ldr x9, [x0, x9]
At this moment the x9 points to the beginning of memory segment containing the data.
Finally, shift the value of fetch index stored in x8 to the left by 3 bits, add it to the x9 and put the contents of memory at that location into x0:
0xc32c ldr x0, [x9, x8, lsl #3]
Two things are important here. First of all, every data offset is in bytes. Shifting a value to the left by 3 is equivalent to multiplying it by 8, which is the size of a pointer on a 64-bit architecture. Secondly, the results goes into x0 which is the register which stores the return value of a function returning NSUInteger.
At this point we are done. We have fetched the correct value stored in array.
Function Epilog
There rest are some boilerplate operations that restore the state of registers and stack pointer before the call. We’re reversing the function’s prologue and returning:
0xc330 mov sp, x29
0xc334 ldp x29, x30, [sp], #0x10
0xc338 ret
Putting it all together
I explained what the code does, but the question we will now answer is why?
The Meaning of ivars
Let’s do a quick summary of what each ivar means:
_usedis count_listis a pointer to the buffer_sizeis size of the buffer_offsetis an index of the first element of the array stored in the buffer
The C code
With ivars in mind and the disassembly analyzed we now can write an equivalent Objective-C code that performs the very same actions:
- (id)objectAtIndex:(NSUInteger)index
{
if (_used <= index) {
goto ThrowException;
}
NSUInteger fetchOffset = _offset + index;
NSUInteger realOffset = fetchOffset - (_size > fetchOffset ? 0 : _size);
return _list[realOffset];
ThrowException:
// exception throwing code
}
Assembly was definitely much more long-winded.
Memory Layout
The most crucial part is deciding whether the realOffset should be equal to fetchOffset (subtracting zero) or fetchOffset minus _size. Since staring at dry code doesn’t necessarily paint the perfect picture, let’s consider two examples of how object fetching works.
_size > fetchOffset
In this example, the offset is relatively low:
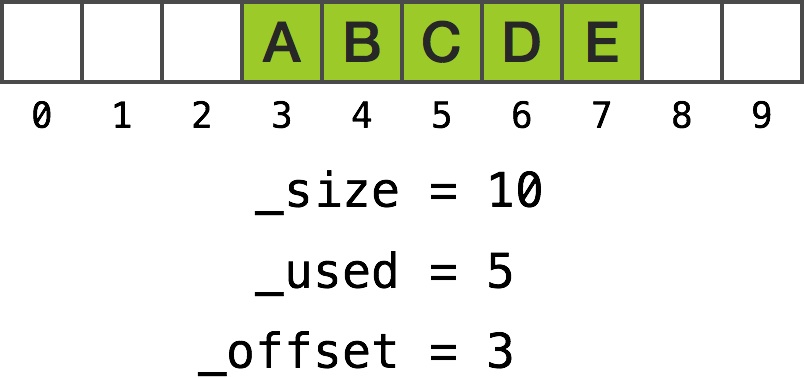
A simple example
To fetch object at index 0 we calculate the fetchOffset as 3 + 0. Since _size is larger than fetchOffset the realOffset is equal to 3 as well. The code returns value of _list[3]. Fetching object at index 4 makes fetchOffset equal to 3 + 4 and the code returns _list[7].
_size <= fetchOffset
What happens when offset is large?
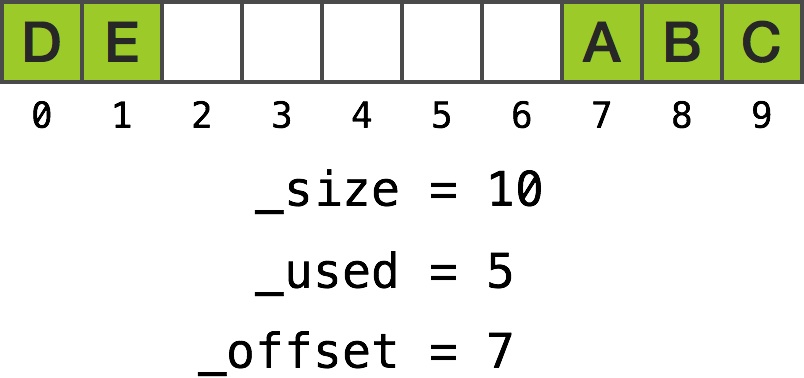
A more difficult example
Fetching object at index 0 makes fetchOffset equal to 7 + 0 and the call returns _list[7] as expected. However, fetching object at index 4 makes fetchOffset equal to 7 + 4 = 11, which is larger than _size. Obtaining realOffset requires subtracting _size value from fetchOffset which makes it 11 - 10 = 1 and the method returns _list[1].
We’re essentially doing modulo arithmetic, circling back to the other end of the buffer when crossing the buffer boundary.
Data Structure
As you might have guessed, __NSArrayM makes use of circular buffer. This data structure is extremely simple, but a little bit more sophisticated than a regular array/buffer. The contents of a circular buffer can wrap around when either end is reached.
Circular buffers have some very cool properties. Notably, unless the buffer is full, insertion/deletion from either end doesn’t require any memory to be moved. Let’s analyze how the class utilizes circular buffer to be superior in its behavior in comparison to a C array.
__NSArrayM Characteristics
While reverse-engineering the rest of the disassembled methods would provide the definite explanation of __NSArrayM internals, we can employ the discovered points of data to investigate the class at a higher level.
Inspecting at Runtime
To inspect __NSArrayM at runtime we can’t simply paste in the dumped header. First of all, the test application won’t link without providing at least empty @implementation block for the __NSArrayM class. Adding this @implementation block is probably not a good idea. While the app builds and actually runs, I’m not entirely sure how does the runtime decide which class to use (if you do know, please let me know). For the sake of safety I’ve renamed the class name to something unique - BCExploredMutableArray.
Secondly, ARC won’t let us compile the id *_list ivar without specifying its ownership. We’re not going to write into the ivar, so prepending id with __unsafe_unretained should not interfere with ARC’s memory management. However, I’ve chosen to declare the ivar as void **_list and it will soon become clear why.
Printout code
We can create a category on NSMutableArray that will print the contents of ivars as wells as the list of all the pointers contained within the array:
|
|
The Results
Insertion and deletion is fast at both ends
Let’s consider a very simple example:
|
|
The output shows that removing object at index 0 twice simply clears the pointers and moves the _offset ivar accordingly:
Size: 6
Count: 3
Offset: 2
Storage: 0x178245ca0
[0] 0x0
[1] 0x0
[2] 0xb000000000000022
[3] 0xb000000000000032
[4] 0xb000000000000042
[5] 0x0
Here’s the visual interpretation of what’s going on:
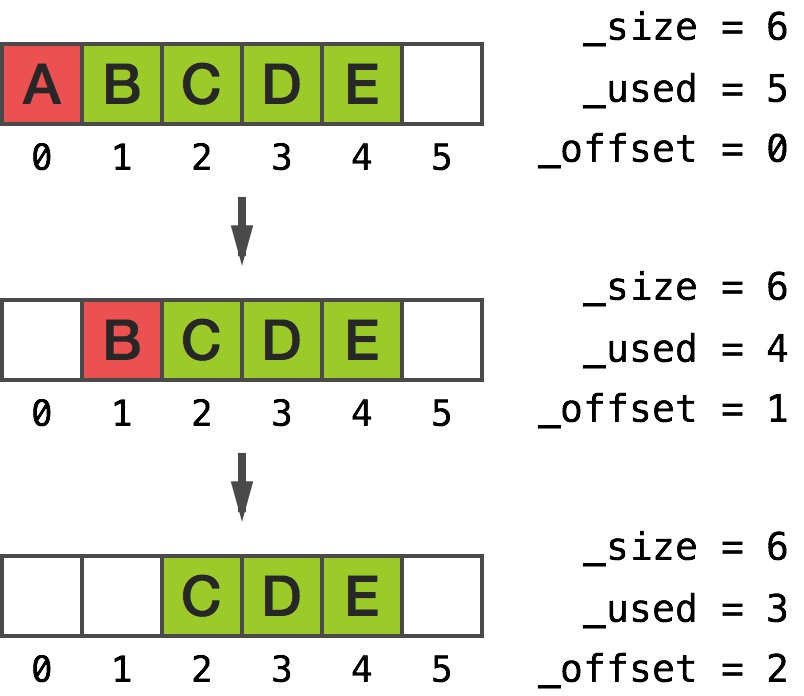
Removing object at index 0 twice
What about adding objects? Let’s run another test on a brand new array:
|
|
Inserting object at index 0 uses the circular buffer magic to put the newly inserted object at the end of the buffer:
Size: 6
Count: 5
Offset: 5
Storage: 0x17004a560
[0] 0xb000000000000002
[1] 0xb000000000000012
[2] 0xb000000000000022
[3] 0xb000000000000032
[4] 0x0
[5] 0xb0000000000000f2
And visually:
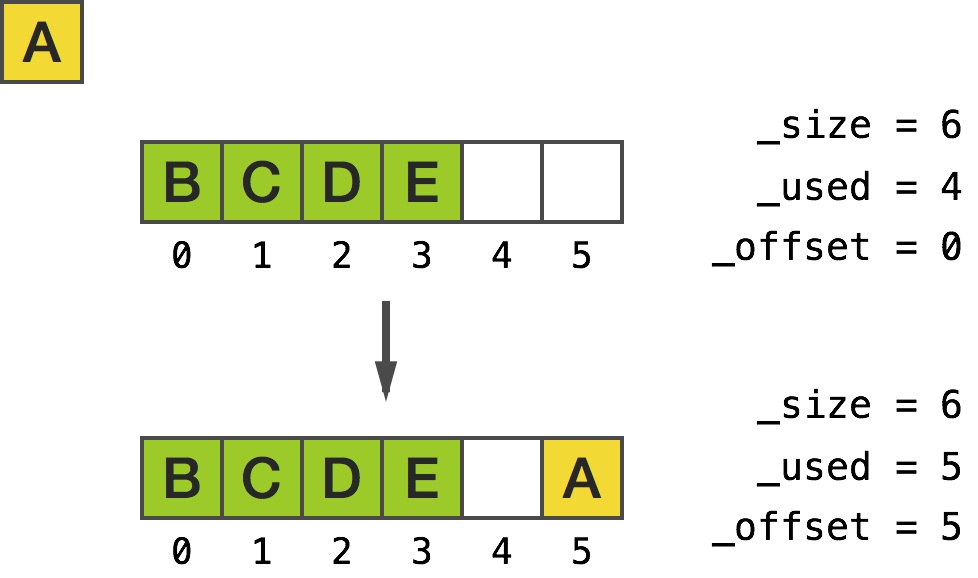
Adding object at index 0
This is fantastic news! It means that __NSArrayM can be processed from either side. You can use __NSArrayM as either stack or queue without any performance hits.
On a side note, you can see how on 64-bit architectures NSNumber uses tagged pointers to do its storage.
Non integral growth factor
OK, for this one I’ve cheated a little bit. While I’ve done some empirical testing as well, I wanted to have the exact value and I’ve peeked into the disassembly of insertObject:atIndex:. Whenever the buffer gets full, it is reallocated with 1.625 times larger size. I was quite astonished for it not to be equal to 2.
Update: Mike Curtiss has provided a very good explanation of why making resizing factor equal to 2 is suboptimal.
Once grown, doesn’t shrink
This is a shocker – __NSArrayM never reduces its size! Let’s run the following test code:
|
|
Even though at this point the array is empty, it still keeps the large buffer:
Size: 14336
This is not something you should worry about unless you use the NSMutableArray to load in some enormous amounts of data and then clear the array with the intention of freeing the space.
Initial capacity almost doesn’t matter
Let’s allocate new arrays with initial capacity set to consecutive powers of two:
|
|
Surprise surprise:
Size:2 // requested capacity - 1
Size:2 // requested capacity - 2
Size:4 // requested capacity - 4
Size:8 // requested capacity - 8
Size:16 // requested capacity - 16
Size:16 // requested capacity - 32
Size:16 // requested capacity - 64
Size:16 // requested capacity - 128
... // Size:16 all the way down
It doesn’t clean up its pointers on deletion
This is barely important, but I found it nonetheless interesting:
|
|
And the output:
Size: 6
Count: 3
Offset: 3
Storage: 0x17805be10
[0] 0xb000000000000002
[1] 0xb000000000000002
[2] 0xb000000000000002
[3] 0xb000000000000002
[4] 0xb000000000000042
[5] 0xb000000000000052
The __NSArrayM doesn’t bother clearing previous space when moving its objects forward. However, the objects do get deallocated. It’s not the NSNumber doing its magic either, NSObject acts correspondingly.
This explains why I’ve opted for defining _list ivar as void **. If the _list was declared as id * then the following loop would crash on the object assignment:
for (int i = 0; i < size; i++) {
id object = array->_list[i];
NSLog("%p", object);
}
ARC implicitly inserts a retain/release pair causing it to access deallocated objects. While prepending id object with __unsafe_unretained fixes the problem, I absolutely didn’t want anything to call any methods on this bunch of stray pointers. That’s my void ** reasoning.
Worst case scenario is adding/removing from the middle
In these two examples we will remove elements from roughly the middle of the array:
|
|
In output we see that the top part shifts down, where down are lower indexes (notice the stray pointer at [5])
[0] 0xb000000000000002
[1] 0xb000000000000012
[2] 0xb000000000000022
[3] 0xb000000000000042
[4] 0xb000000000000052
[5] 0xb000000000000052
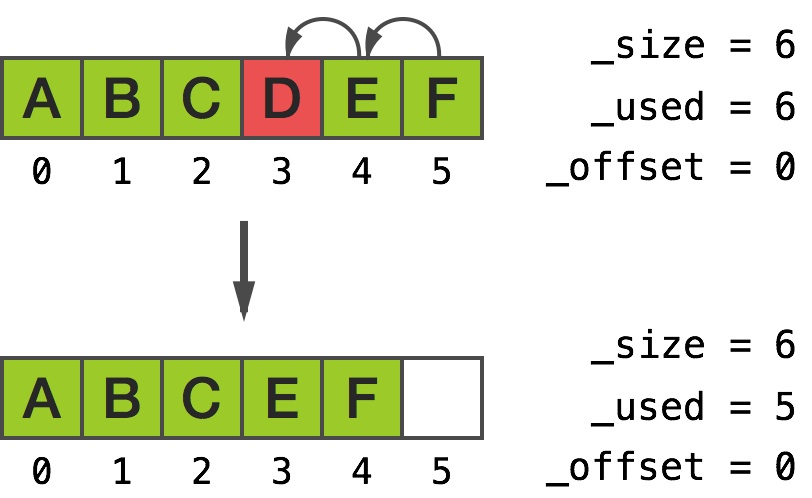
Removing object at index 3
However, when we call [array removeObjectAtIndex:2] instead, the bottom part shifts up, where up are higher indexes:
[0] 0xb000000000000002
[1] 0xb000000000000002
[2] 0xb000000000000012
[3] 0xb000000000000032
[4] 0xb000000000000042
[5] 0xb000000000000052
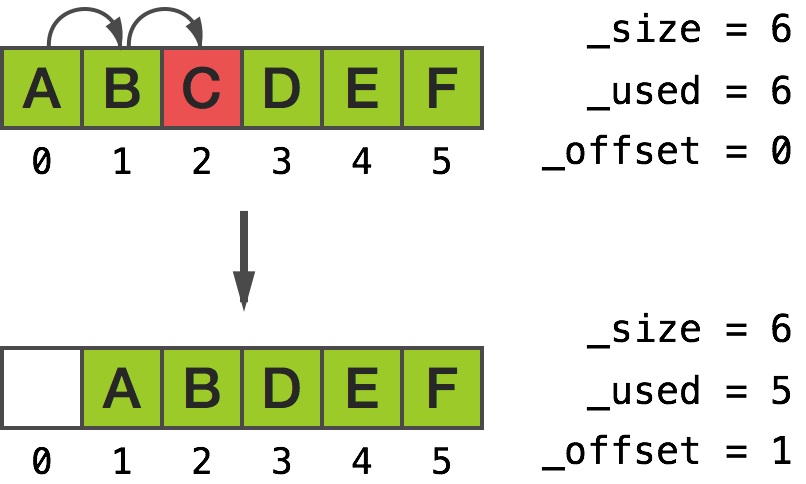
Removing object at index 2
Inserting object in the middle has very similar results. The reasonable explanation is __NSArrayM tries to minimize the amount of memory moved, thus it will move at most half of its elements.
Being a Good Subclassing Citizen
As discussed in NSMutableArray Class Reference every NSMutableArray subclass must implement the following seven methods:
- count- objectAtIndex:- insertObject:atIndex:- removeObjectAtIndex:- addObject:- removeLastObject- replaceObjectAtIndex:withObject:
Unsurprisingly, __NSArrayM fulfills this requirement. However, the list of all the methods implemented by __NSArrayM is quite short and doesn’t contain 21 additional methods listed in NSMutableArray header. Who’s responsible for executing those methods?
It turns out they’re all part of the NSMutableArray class itself. This is extremely convenient – any subclass of NSMutableArray can implement only the seven most rudimentary methods. All the other higher-level abstractions are built on top of them. For instance - removeAllObjects method simply iterates backwards, calling - removeObjectAtIndex: one by one. Here’s pseudo code:
|
|
However, where it makes sense __NSArrayM does reimplement some of its superclasses' methods. For instance, while NSArray provides the default implementation for - countByEnumeratingWithState:objects:count: method of NSFastEnumeration protocol, __NSArrayM has its own code-path as well. Knowing its internal storage __NSArrayM can provide much more efficient implementation.
Foundations
I’ve always had this idea of Foundation being a thin wrapper on CoreFoundation. My argument was simple – there is no need to reinvent the wheel with brand new implementations of NS* classes when the CF* counterparts are available. I was shocked to realize neither NSArray nor NSMutableArray have anything in common with CFArray.
CFArray
The best thing about CFArray is that it’s open sourced. This will be a very quick overview, since the source code is publicly available, eagerly waiting to be read. The most important function in CFArray is _CFArrayReplaceValues. It’s called by:
- CFArrayAppendValue
- CFArraySetValueAtIndex
- CFArrayInsertValueAtIndex
- CFArrayRemoveValueAtIndex
- CFArrayReplaceValues (notice the lack of leading underscore).
Basically, CFArray moves the memory around to accommodate the changes in the most efficient fashion, similarly to how __NSArrayM does its job. However, the CFArray does not use a circular buffer! Instead it has a larger buffer padded with zeros from both ends which makes enumeration and fetching the correct object much easier. Adding elements at either end simply eats up the remaining padding.
Final Words
Even though CFArray has to serve slightly more general purposes, I find it fascinating that its internals don’t work the same way as __NSArrayM does. While I suppose it would make sense to find common ground and make a single, canonical implementation, perhaps there are some other factors that influenced the separation.
What those two have in common? They’re the concrete implementation of abstract data type known as deque. Despite its name, NSMutableArray is an array on steroids, deprived of C-style counterpart’s drawbacks.
Personally, I’m most delighted with constant-time performance of insertion/deletion from either end. I no longer have to question myself using NSMutableArray as queue. It works perfectly fine.